Data Crawling vs Data Scraping: Detailed Comparison
There are several ways to get information and data from the Internet. The two most popular ways are Data Crawling (also known as Web Crawling) and Data Scraping (or Web Scraping) as called. Both web crawling and data scraping are methods of retrieving data and the information required and processes involved in gaining them. We can opt for either technique depending on the nature of information we are looking up.
Today we look more in detail about two most popular and widely used techniques, data scraping and data crawling, in which kind of scenario the most suitable one, understand their differences, use cases etc.
About Data crawling
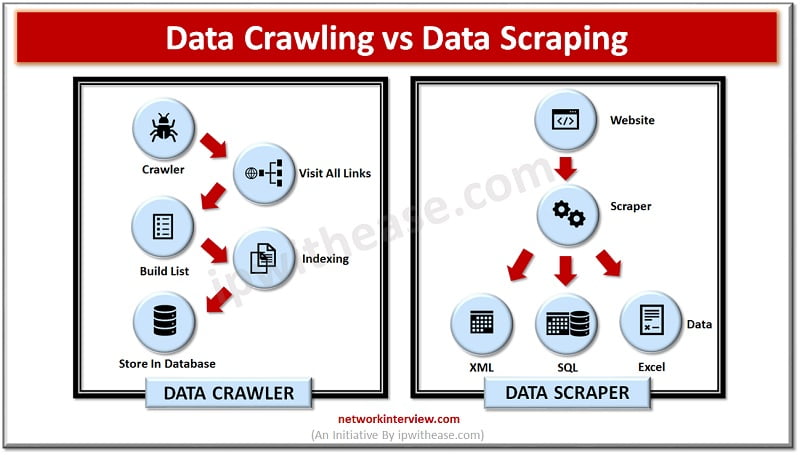
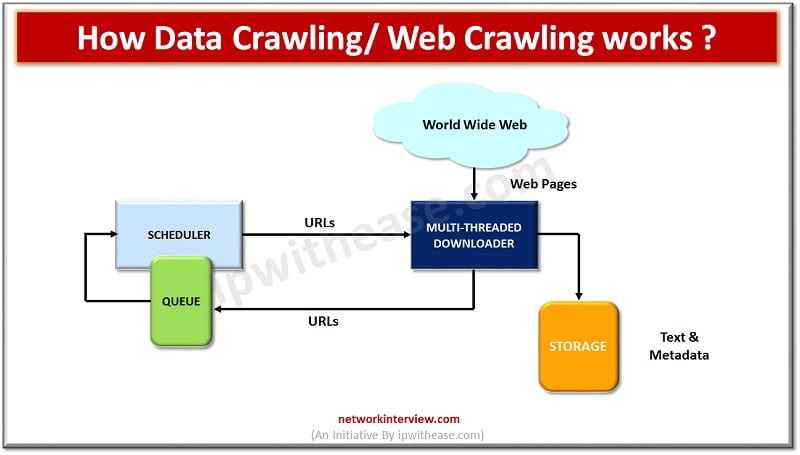
Data crawling or Web crawling as called is a process in which information is located on the internet, all compiled words found in a document are added to a database and then follow all hyperlinks and indexes related to that data or information into their databases. This function is usually performed by web spiders or bots.
It is an Internet Bot program which assists in web indexing. It browses through the Internet in a systematic manner and looks up for keywords in every page, kind of content it contains, links etc. it follows instructions based on an algorithm and helps in checking links and validating HTML codes. Google and Bing are two of the most popular web crawlers.
Web crawlers have been evolving for years and they possess certain qualities which make them more desirable. Web crawler architecture comprises supervisory crawlers which are responsible for managing worker crawlers who work on the same link. Intelligent re-crawling is an essential feature for a web crawler to analyse at what frequency pages are updated on websites.
Scalability of a crawler system is of significant importance while rolling it out. Data is usually compressed by crawler before fetching it. Data crawling bots are language neutral and support multilingual capabilities which allows users to request for data in any language and enable them to make informed business decisions using data crawling systems.
About Data scraping
Data scraping/Web Scraping objective is to find the right data and extract it from the page. Data scraping may not necessarily be from a web page only it can be obtained from any other place. This may include a variety of resources such as storage devices, spreadsheets, databases, notes etc. so in a larger sense data scraping does not mean that data is extracted only from a website or a webpage on the Internet.
Data scraping is useful where it is difficult to extract data otherwise. In addition, data scraping has additional functionalities such as JavaScript execution, submission of data forms, and disobeying robots. Scraper’s bot conducts data scraping. The data scraper bot sends an HTTP GET request, once the request is received it dissects and analyses the content and structure of data and converts it into a format preferred by the BOT author.
Functions of Data Scraper BOT:
- Content Scraping – is used to duplicate the specific advantage of a product or service that relies on the content. Such as if a product relies on its reviews, a rival company could scrap all review content and replicate it to their website showcasing it as original.
- Contact Scraping – contact details like email address, phone numbers, location etc. can be scraped and combined for bulk mailing lists or for social engineering attempts. Usually used by spammers and scammers to identify new targets.
- Price Scraping – is used by competitors to use your pricing data for their own benefits. By getting details regarding your pricing, they can drive attention to their page.
Comparison Table: Data Crawling vs Data Scraping
Below table summarizes the difference between two:
PARAMETER | DATA SCRAPING | DATA CRAWLING |
| Definition | Data extraction from multiple sources such as a local machine or database including web sites | Specific to downloading data from web sites and web pages |
| Features |
|
|
| Examples | WebHarvy, Octoparse, import.io, Parsehub etc | Amazon Bot, Googlebot, Yahoo, Bingbot etc. |
| Use cases | Lead Generation for Marketing, Price Comparison, Academic Research etc. | Machine learning training data collection, Price intelligence data collection, Fetching product data etc. |
Download the Comparison table: Data Crawling vs Data Scraping
Continue Reading:
Tag:comparison