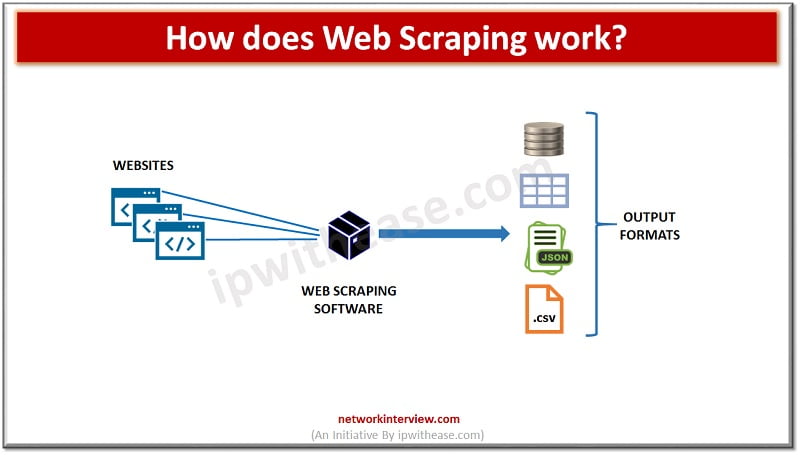
What is Web Scraping?
Access to relevant data and having ways and techniques to analyse it makes a huge difference in the success of organizations and faster growth. Data collection and its analysis is very important for government, public and private sector firms and also educational institutes. Usually, the data displayed on websites can only be viewed using a web browser. At times copy paste option is also disabled on sites. So, you need the data – it is a very tedious job to complete and it may take hours , days and weeks. The technique to automate this is known as scraping.
In this article, we will learn more about Web scraping technique and how it works, what it is used for , its features, functions and limitations and so on.
What is Web Scraping?
Web scraping is also known as crawling, spidering, Screen scraping, web data extraction, web harvesting etc. In this technique large amounts of data automatically extracted from websites and stored in a file or a database. The data scrapped is usually be in tabular or spreadsheet format. Instead of manually copying data from websites – web scraping software is used to perform same tasks with much less effort and off course the time.
Web scraping software automatically load, crawl and extract data from multiple pages of websites based on the need it could be either custom built or specific website.
Web scraping has two functional parts ,
- one is crawler and
- other is scraper.
The crawler is an artificial intelligence algorithm which is used to browse the web to locate a particular data required by following the links across the internet. The scraper is a specific tool which is created to extract data from the website.
Uses of Web Scraping
There are many uses of Web scraping in varied businesses as under :
- In E-commerce web sites scraping is used to perform price comparisons and monitoring of competitors
- In marketing web scraping is used for lead generation, build phone and email contact lists for cold calling
- In Real Estate web scraping is used to collect property details and contact details of owners and agents
- Web scraping is used to collect training data for machine learning modules
Ways to scrap data from websites?
Web scraping software’s fall under two types.
System-based
First one which can be installed locally on system. WebHarvy, OutWit hub, visual web Ripper etc. are some examples of system-based web scraping software.
Cloud-based
Second one which runs on cloud. Examples of cloud-based web scarping software are import.io, Mozenda, ParseHub , OctoParse etc.
Web scraping software can be custom built for specific requirement usually through a hired developer who will use a common API such as apify.com to scrape data from any website.
How is Web Scraping performed?
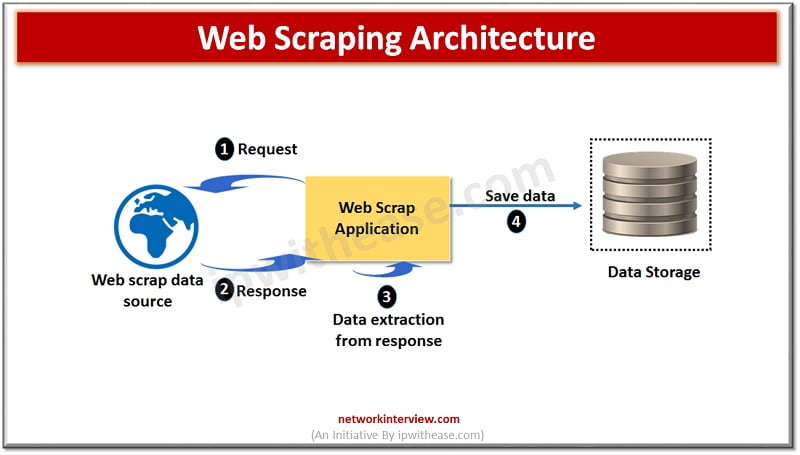
Implementation of web scraping is done via a small code which is used to get information from the website and known as scraper bot. The bot initiates a GET request to web site.
When a response is received from website, scraper parses the HTML document in a specific data pattern and after parsing the bot converges data into format programmer had designed in the bot could be a spreadsheet or tabular format.
Scraper bots are used for variety of tasks such as Price scraping to compare between markets competition, promotional emails, WhatsApp promotions etc. are part of contract scraping which steals data from eCommerce sites and use it to promote their brand and products.
Protection from malicious Web scraping ?
Another form of scraping is content scraping where entire content is copied and pasted and can be misused by a fraudulent website.
Web scraping is considered malicious and illegal when data is extracted without the consent of website owners. The most widely use case for such kind of scarping is price and content theft. To counter the attempts made by bot scrapers several techniques are used such as HTML fingerprinting , IP reputation, Behaviour analysis and progressive challenges such as CAPATCH challenge.
Continue Reading:
Data Crawling vs Data Scraping: Detailed Comparison
You may also like

Top 10 Network Threats & How NDR Detects Them