What Is Data Masking? Types & 8 Techniques
Data breaches are costing organizations very expensive and every year exposing millions of people’s sensitive data resulting businesses to lose millions. Data breaches in year 2021 estimated to average cost of $4.24 million. Personally Identifiable and sensitive personal information is the costliest type of data among compromised types of data. Consequently, data protection is top priority of many organizations and businesses are most concerned around personal data security measures providers are taking to safeguard them.
Today we look more in detail about data masking, data masking types, data masking techniques etc.
What is Data Masking?
Data masking is an umbrella term for anonymization of data, pseudonymization of data, redaction, scrubbing, or de-identification. All meant for protection of sensitive data by replacing original value with fabricated but realistic equivalent. Data masking is also referred to as ‘data obfuscation.’
Data masking platforms usually replace sensitive data sets in a data repository with similar data values which retain part of the original data value. The objective is to provide data which looks and acts like original data but not sensitive in nature and does not pose risk of exposure. This in turn reduces scope and complexity of security efforts and mask should make it impossible to reverse engineer masked data values back to original data without special additional information.
There are several types of data which we cant to protect using data masking technique, common types of data which could be ideal for masking includes:
- PII – Personally Identifiable Information
- PHI or e-PHI – Electronic-Protected Health Information / Protected Health Information
- PCI-DSS – Payment industry card information
- ITAR – Intellectual property Information
Masking is a generic term which encompasses several possible data masking techniques. In a broader sense data masking may mean – collection of data, obfuscation of data, storage of data, and possible movement of the masked information or data. In the upcoming section, we will explore more in detail about data masks used to obfuscate data and how its functionalities differ.
Data Masking Techniques
- Substitution – is replacement of one value with another. For example, masks substitute a person’s first name and last name with some random numerical digits. The actual data still is a name but there is no logical relationship with the original first, last name unless access to the original substitution table is there.
- Redaction/Nulling – In this form of masking sensitive data is replaced with generic values such as ‘X.’ For example, a phone number is replaced as (XXX)-XXX-XXXX DOB as (XX/XX/XXXX).
- Shuffling – is a technique to randomize existing values vertically across a data set. For example , shuffling individual values in the salary column in a table of employee’s data but aggregated or average values in the table will not change. This is a common technique used to disassociate sensitive personal data relationships
- Transposition – means swap one value with another or a portion of one string with another string. It is a complex mechanism having many variations for example swapping credit card number last 4 digits swapped.
- Averaging – Individual numeric values are replaced with a value derived by averaging a portion of individual numeric values. For example, substitute individual salaries with average across a group or unit to hide individual salary values while preserving aggregate relationships with actual data.
- De-identification – process of stripping of any identifying information such as who and how the data set was produced or personal identities within the data set.
- Tokenization – data elements are substituted with random placeholder values. Tokens are not reversible as tokens bear no logical relationship with actual value.
- Format preserving encryption – transforming data into an unreadable format and any given value will provide the same result.
Types of Data Masking
Let’s look at some common types of data masking based on its usage.
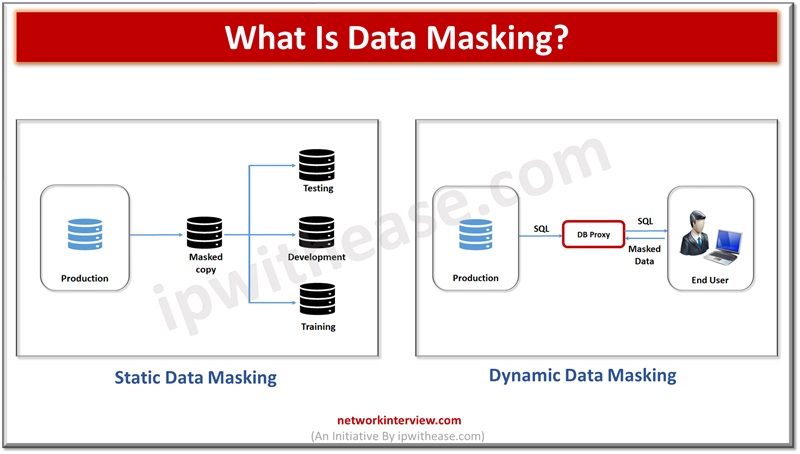
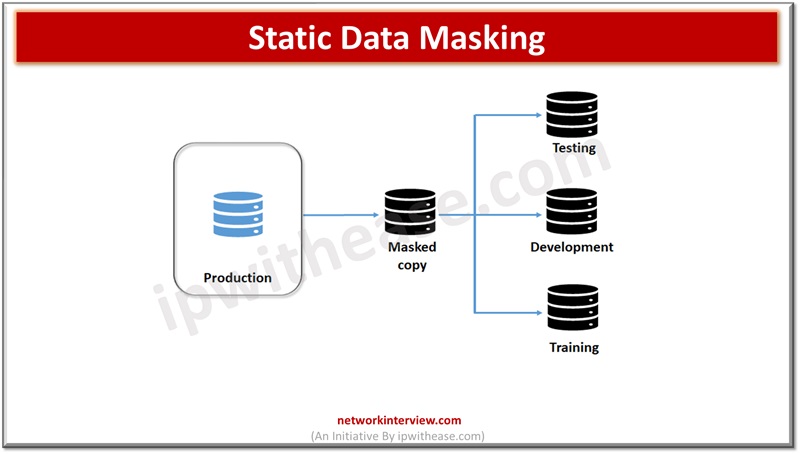
Static Data Masking (SDM) – mainly works on copies of databases in production. Data is backed up or a golden copy of the production database is taken to another environment. Unnecessary data is removed and masked while in a static state.
Dynamic Data Masking (DDM) – happens at run time and streaming of data directly to the production system so there is no need to store masked data in another database. It is used mostly for processing role-based security in applications.
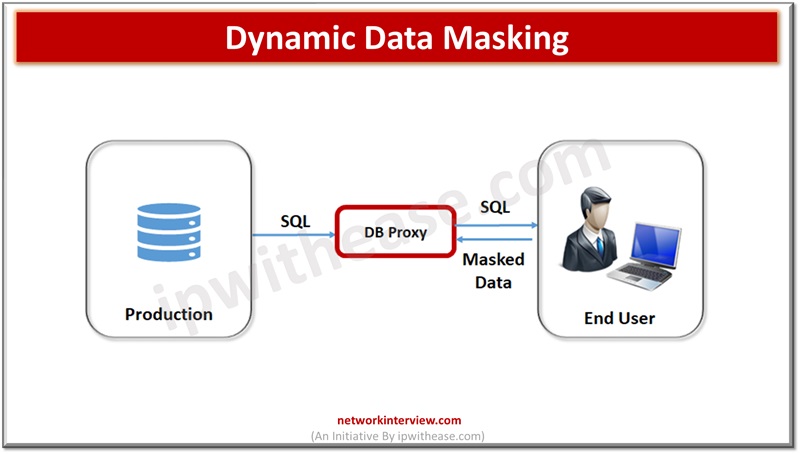
Importance of Data Masking
- Help companies to maintain compliance to regulations such as General Data Protection Regulation (GDPR) by elimination of risk to sensitive data exposure.
- Making data meaning less for cyber attackers while maintaining its consistency and usability
- Reduction is risks associated to data sharing with third party applications and cloud hosted applications
- Avoidance of risks associated while outsourcing any projects by masking data to prevent its misuse or stealing
Continue Reading:
Tag:Security